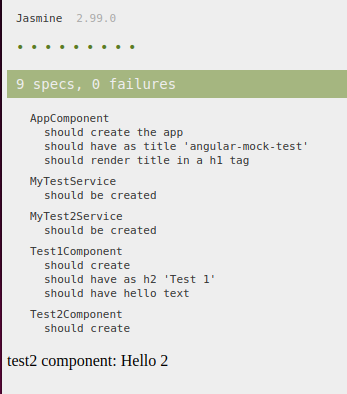
For software developers is a good keyboard essential, I use a keyboard much more than a mouse.

Many years I used the Logitech K750 keyboard – this is a very thin keyboard with tiny solar panels. In normal office lighting conditions, you never need to charge the keyboard, it actually doesn’t have any USB ports to charge it with. After a few years, the chargeable button cell fails – Logitech does not want you to replace the battery, but it is possible, just search Youtube. This keyboard lasted many years and I have used 3 of those. Unfortunately Logitech does not make them anymore so I looked for a replacement.
I have been searching for an affordable keyboard that can fit in my backpack. Since I don’t use the numerical part of the keyboard, I used the Logitech K380. This one is very compact and also supports Bluetooth – you can pair it with your smartphone or tablet. Since it is very compact, it fits very well in my backpack.

The keys on this keyboard feel very nice and I thought this was a good replacement. After using it for several weeks, it started annoying me that I made more typing mistakes than I was used to. Because this keyboard is so compact, the spacing of the keys is also smaller – the distance from the q to the p key is 163 mm. On a regular keyboard, this distance is 172 mm. It doesn’t seem much, but is makes a big difference in typing. After using the compact K380, my hands feel a bit cramped. That, combined with the typing mistakes made me consider other keyboards.
I tried the Logitech K360, that one has a full size 172 mm layout, but the keys are smaller and a bit mushy. I also missed (also a problem with the K380) the easy access of the home, end and page up/down keys.

I saw the Logitech MX Keys in the store and they seemed nice, but I thought that the price of 115 euros was ridiculously high. But, after some more suffering from my previous keyboards I decided to purchase one. I found it for sale at 90 euros at alternate.nl.

At first glance, this is a very solid keyboard – the base is made from metal and it has substantial weight. It has backlight key illumination – very nice, but I hardly use it, since I don’t work in the dark. You charge it up with a USB C cable and will require only very infrequent (5 months) charging. It support the usual Logitech USB unifying dongle and also Bluetooth.
The typing experience is just great – no clicky keys, but nice firms keys with a good feedback. It’s a pity that this keyboard doesn’t come as a smaller tenkeyless version; I want the home, end, page up/down keys, but I don’t need the digits keypad. It fits in my backpack, but it is large and heavy. The media keys at the top are surprisingly useful, even in Ubuntu Linux. The escape key is large and makes Intellij and vim much easier to use. Because Logitech added support for the Mac, the start and alt keys are a bit messy with opt and cmd symbols, but you get used to it.
In conclusion, I love the Logitech MX keys. I think that it is the best keyboard I ever used.